CHEETAH
CHallenges of Evaluating Teams and Algorithms
Description
Machine learning (ML) competitions are often touted as drivers of algorithm development in healthcare but face limitations in real-world applications. An example competition is detecting lung cancer in chest images, where the team correctly identifying the most images with cancer wins the competition. Such competitions attract many international teams with monetary or prestigious incentives. While competitions are said to spur innovation, they often result in too similar algorithms that only excel on a specific accuracy metric, but are not robust and fail to generalize to diverse, real-world data.
A single performance metric such as accuracy is insufficient to capture algorithm robustness, for example how the algorithm performs on rare patient cases. Having a single performance metric also leads to too similar algorithms which do not bring added value despite their high training costs and carbon footprint. Furthermore, as research on women and other underrepresented groups in computer science shows, competition may deter them from entering or staying in the field.
Our goal is to design competitions with multiple metrics, both in what the metric measures and which subgroups of patients this is measured on. We plan to:
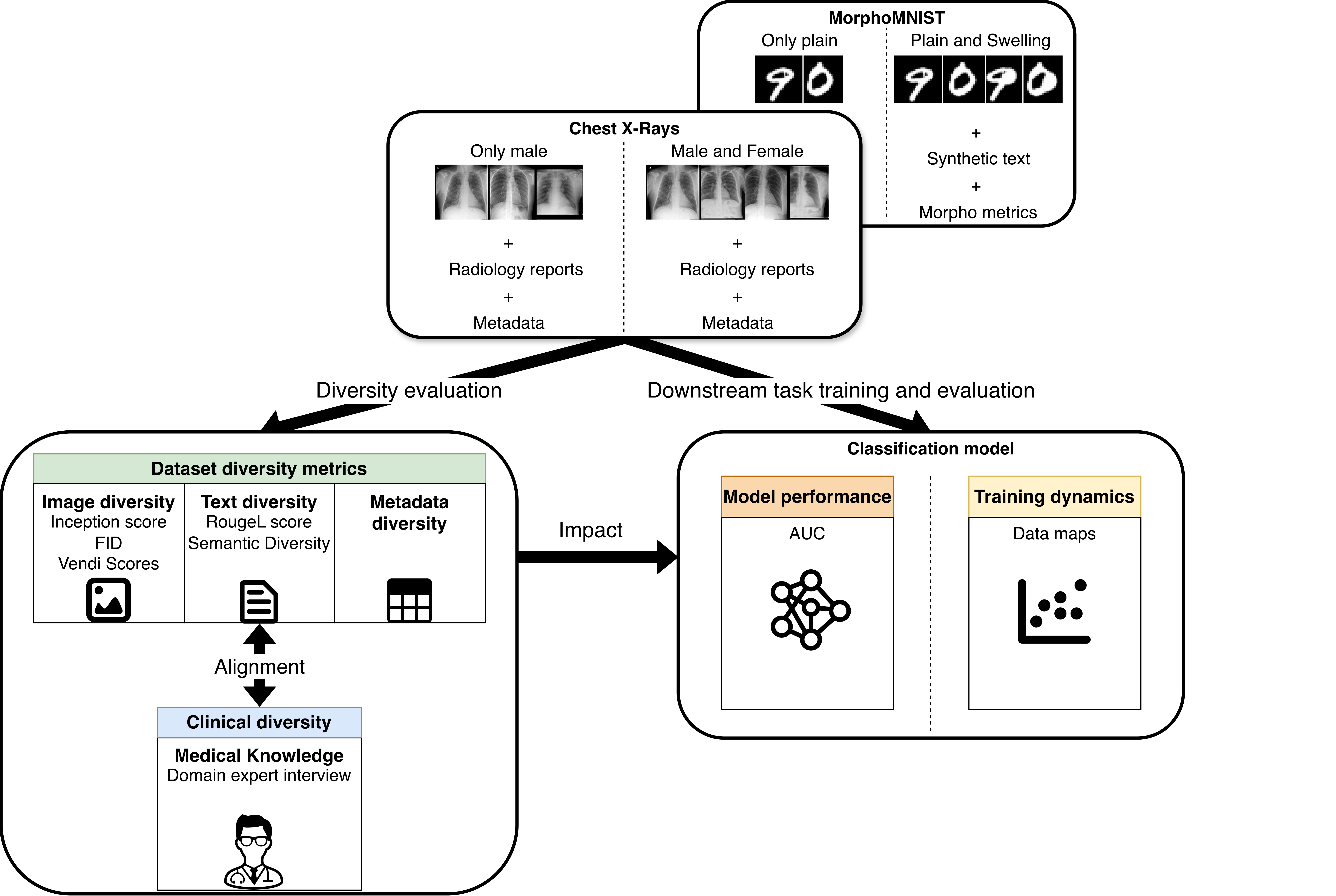
- Develop novel methods to evaluate and increase the diversity of the evaluation data.
- Design how to evaluate similarity of algorithms, and develop methods to combine and reuse (parts of) them, such that robustness can be increased without the disproportionate carbon footprint.
- Organize competitions in education and at conferences, where we will study how the novel design affects underrepresented groups in data science.
People
Théo Sourget, Veronika Cheplygina, Niclas Claßen, Beatrix M. G. Nielsen.
References
-
 arXiv preprint arXiv:2603.15276, 2026
arXiv preprint arXiv:2603.15276, 2026
Funding
Novo Nordisk Data Science Investigator Grant (grant number NNF24OC00926)