MMC
Making Meta-Data Count
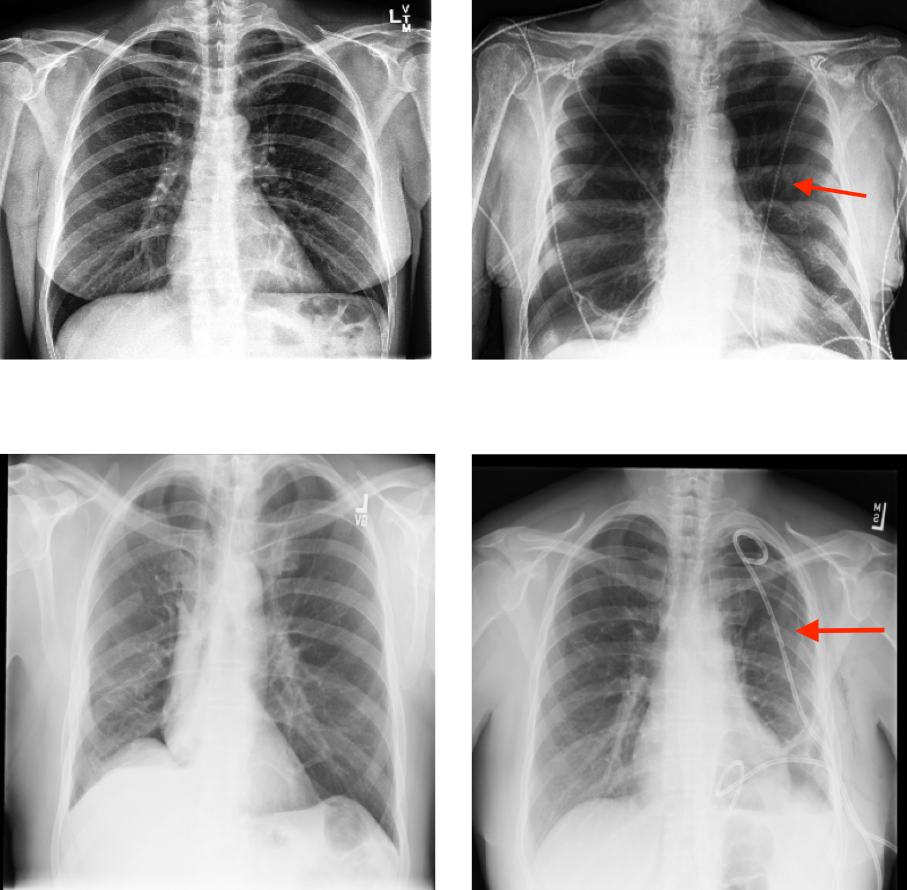
Machine learning has shown promising results in medical image diagnosis, at times with claims of expert-level performance. The availability of large public datasets have shifted the interest of the medical community to high-performance algorithms. However, little attention is paid to the quality of the data or annotations. Algorithms with high reported performances have been shown to suffer from overfitting or shortcuts, i.e. spurious correlations between artifacts in images and diagnostic labels. Examples include pen marks in skin lesion classification, patient position in detection of COVID-19, and chest drains in pneumothorax classification. Performance may appear high when training and evaluating on data with shortcuts, but degraded when the shortcut is removed. This happens because the algorithm cannot generalize based on the actual features related to the diagnosis.
Our goal is to redefine how meta-data is used and thus improve the robustness of algorithms. We plan to:
- investigate what kind of different shortcuts (based on demographics or image artefacts) might occur and how these affect the performance and fairness of the algorithms ⚖️.
- investigate meta-data-aware methods to try to avoid learning biases or shortcuts ⚔️🛡.
Some students have done work related to this project:
- Bianca Ida Pedersen and Max Andreas de Visser investigated shortcuts in 3D lung nodules using the publicly available LIDC-IDRI dataset.
- Casper Anton Poulsen and Michelle Hestbek-Møller explored generating synthetic X-ray images using SyntheX.
- Trine Naja Eriksen and Cathrine Damgaard developed a chest drain detector with their non-expert annotations that generalizes well to expert labels.
- Paula Victoria Menshikoff and Katarina Kraljevic investigated shortcut learning across different demographic attributes for chest X-ray classification.
People
Amelia Jiménez-Sánchez, Théo Sourget, Veronika Cheplygina.
Webinar
We are organizing a webinar series: Datasets through the L👀king-Glass to better understand what researchers are doing with their (meta-) data.
Workshop
We organized a 2-days workshop in Nyborg Strand (DK) In the Picture: Medical Imaging Datasets focused on the challenges within medical imaging datasets that hinder the development of fair and robust AI algorithms. We had several invited talks, and mostly group sessions that focused on engagement and collaboration.
Dataset
NEATX: Non-Expert Annotations of Tubes in X-rays, hosted on Zenodo.
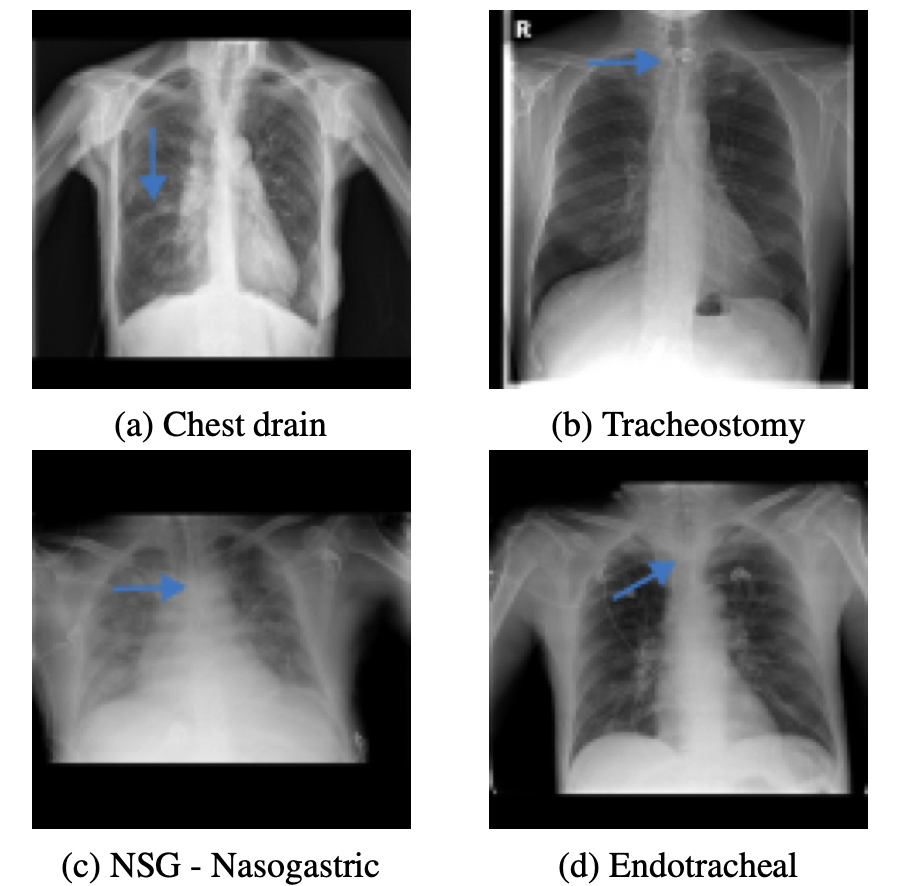
This dataset contains 3.5k chest drain annotations for the NIH-CXR14 dataset, and 1k annotations for four different tube types (chest drain, tracheostomy, nasogastric, and endotracheal) in the PadChest dataset by two data science students.
References
-
 In Medical Image Understanding and Analysis, 2026
In Medical Image Understanding and Analysis, 2026 -
 In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, , 2025
In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, , 2025 -
 arXiv preprint arXiv:2510.00902, 2025
arXiv preprint arXiv:2510.00902, 2025 -
 In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024 -
 In 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), 2023
In 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), 2023
Funding
DFF (Independent Research Council Denmark) Inge Lehmann 1134-00017B